我们现在可以与几乎所有小工具交谈,但是它究竟如何工作?当您问``这是什么歌?''或说``给妈妈打电话''时,现代科技的奇迹正在发生。虽然感觉像是最前沿的,但这种与设备交谈的想法可以追溯到几十年前-几乎与科幻小说中的喷气背包一样!
如今,语音驱动计算的大部分关注在智能手机上。苹果,亚马逊,微软和谷歌位居榜首,它们各自提供与电子产品交谈的方式。您知道他们是谁:Siri,Alexa,Cortana和无名的“ Ok,Google"。这就提出了一个大问题...
设备如何将口语转换成可以理解的命令?从本质上讲,它可以归结为模式匹配和基于这些模式进行预测。更具体地说,语音识别是一项复杂的任务,来自声学建模和语言建模。
声学建模:波形和电话
声学建模是获取语音波形并使用统计模型对其进行分析的过程。最常见的方法是 Hyden Markov Modeling (隐藏马尔可夫建模),该方法用于所谓的语音建模中,以将语音分解为称为电话的组成部分(不要与实际的电话设备混淆)。微软多年来一直是该领域的领先研究者。
隐马尔可夫建模是一种预测性数学模型,其中通过分析输出确定当前状态。 Wikipedia有一个使用两个朋友的好例子。
Imagine two friends — Local Friend and Remote Friend — who live in different cities. Local Friend wants to figure out what the weather is like where Remote Friend lives, but Remote Friend only wants to talk about what he did that day: walk, shop, or clean. The likelihood of each activity depending on the day’s weather.
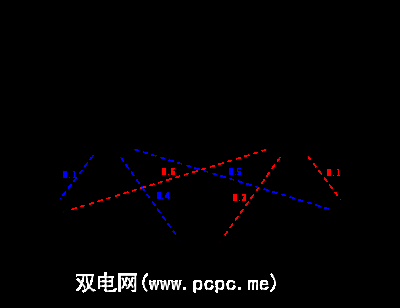
假装这是唯一可用的信息。有了它,“本地朋友"可以发现天气每天变化的趋势,并利用这些趋势,可以根据朋友昨天的活动开始对今天的天气做出有根据的猜测。 (您可以在上面看到系统的示意图。)
If you want a more complex example, check out this example on Matlab. In voice recognition, this model essentially compares each part of the waveform against what comes before and what comes after, and against a dictionary of waveforms to figure out what’s being said.
本质上,如果您发出“ th"声音,它将与该声音前后最可能出现的声音进行对比。也许这意味着要检查“ e"声音,“ at"声音等等。模式正确匹配后,便可以说出完整的单词。这是一个过分的简化,但是您可以在此处看到Microsoft的完整说明。
语言建模:比声音更重要
声学建模在帮助您的计算机理解您方面大有帮助,但是谐音和发音的区域差异如何?这就是语言建模的作用。 Google在这方面进行了大量研究,主要是通过使用 N-gram建模来实现的。
当Google试图理解您的语音时,它是基于模型的源自其庞大的语音搜索和YouTube转录库。所有这些荒谬的错误视频字幕实际上都帮助Google扩展了词典。此外,他们还使用了已故的GOOG-411来收集有关人们怎么说的信息。声音。与基于原始概率的蛮力匹配相比,这允许具有大大降低的错误率的匹配。您可以在此处阅读描述其方法的简短论文。
虽然Google在该领域处于领先地位,但仍在开发其他数学模型,包括连续空间模型和位置语言模型,这是更先进的技术来自人工智能研究。这些方法基于复制人类在彼此倾听时所做的推理。无论是在其背后的技术方面,还是在绘制这些模型所需的数学和编程方面,这些技术都更为先进。
N-gram建模基于概率工作,但它使用现有的字典单词来创建可能性的分支树,然后出于效率考虑对其进行平滑处理。从某种意义上讲,这意味着N元语法建模消除了前面提到的隐马尔可夫建模中的许多不确定性。
如上所述,该方法的优势来自于拥有大量的字典单词和用法,而不仅仅是原始的声音。这使程序能够分辨同音字之间的区别,例如“拍"和“甜菜"。这是上下文相关的,这意味着当您谈论昨晚的成绩时,该程序并没有提起关于罗宋汤的字眼。
但是这些模型实际上并不是最佳的语言,主要是由于问题具有较长短语中单词的概率。当您在一个句子中添加更多单词时,此模型会有所减少,因为您的早期单词不太可能加载完整思想所需的所有内容。
但是,它很容易实现,很容易实现对于像Google这样喜欢在计算问题上投入服务器的公司来说,这是一个很好的选择。您可以在华盛顿大学的N-gram Modelieng上做进一步的阅读,或者在Coursera上观看讲座。
在Clouds:Apps&Devices
大喊大叫的人使用Siri知道网络连接速度慢的挫败感。这是因为您发送给Siri的命令是通过网络发送的,由Apple解码。 Windows电话的Cortana也需要网络连接才能正常运行。相反,亚马逊的Echo只是一个蓝牙扬声器,没有任何互联网。
为什么有区别?因为Siri和Cortana需要重型服务器才能解码您的语音。可以在手机或平板电脑上完成吗?可以,但是您会在此过程中牺牲性能和电池寿命。将处理工作转移到专用机器上更有意义。
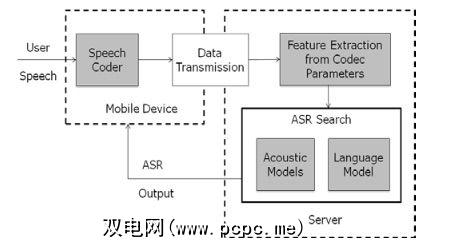
这样想:您的命令是一辆陷入泥潭的汽车。您可能需要花费足够的时间和精力自己将其推出,但是这将花费数小时并且使您筋疲力尽。相反,您致电路边援助,他们在短短几分钟内将您的汽车拉出。缺点是您必须拨打电话并等待他们,但这样做仍然更快且省钱。
像Nuance这样的台式机模型由于硬件功能更强大而倾向于使用本地资源。毕竟,用史蒂夫·乔布斯(Steve Jobs)的话来说,您的台式机是一辆卡车。 (这使OS X使用服务器进行处理有点愚蠢。)因此,当您需要处理语言和语音时,它已经具备了足够的能力来自行处理。
另一方面Android允许开发人员在其应用程序中包含离线语音识别功能。 Google喜欢领先于技术,您可以打赌,随着其他平台的硬件功能越来越强大,其他平台也将获得这种能力。没有人喜欢它,因为覆盖范围差或接收不良使他们的设备变得笨拙。
立即开始使用语音命令
现在您已经了解了基本概念,应该尝试使用各种设备。尝试在Google文档中输入新的语音。好像Web Office套件还不够强大,语音控制使您可以完全口述和格式化文档。这是他们已经为Chrome和Android设计的强大技术的扩展。
其他想法包括设置Mac以使用语音命令。
您最喜欢的语音用法是什么控制?在评论中让我们知道。
图片来源:通过Shutterstock的T-flex,通过Wikimedia Foundation的Terencehonles,亚利桑那州,通过Shutterstock的Cienpies Design
标签: Amazon Echo Microsoft Cortana OK Google Siri 语音命令