我们一直在谈论计算机对我们的理解。我们说Google``知道''我们要搜索的内容,或者说Cortana``了解了''我们所说的内容,但是``了解''是一个非常困难的概念。
计算语言学的一个领域称为自然语言处理(NLP),正在解决这一特别棘手的问题。现在这是一个引人入胜的领域,一旦您了解了它的工作原理,您将开始在各处看到它的效果。
快速注释:电脑响应语音的几个示例,例如当您向Siri询问某些内容时。将可听语音转换为计算机可理解的格式称为语音识别。 NLP对此并不关心(至少在我们这里讨论的能力范围内)。 NLP仅在文本准备好后才起作用。这两个过程对于许多应用程序都是必需的,但是它们是两个非常不同的问题。
定义理解
在我们开始研究计算机如何处理自然语言之前,我们需要定义一些事物。
首先,我们需要定义自然语言。这很简单:人们经常使用的每种语言都属于这一类。它不包括构造语言(克林贡语,世界语)或计算机编程语言之类的东西。与朋友交谈时,您会使用自然语言。您也可能会用它与您的数字个人助理交谈。
那么当我们说理解时,我们指的是什么?好吧,这很复杂。理解句子是什么意思?也许您会说这意味着您现在已经在脑海中有了消息的预期内容。理解一个概念可能意味着您可以将该概念应用于其他思想。
词典定义是模糊的。没有直观的答案。几个世纪以来,哲学家一直在争论这样的事情。

出于我们的目的,我们要说理解是从自然语言中准确提取含义的能力。为了使计算机能够理解,它需要准确地处理传入的语音流,将该语音流转换为含义单元,并能够以有用的东西来响应输入。
显然,这都是非常模糊的。但这是我们在有限的空间(没有神经哲学学位)下可以做的最好的事情。如果计算机可以对自然语言输入流提供类似人的或至少有用的响应,则可以说它可以理解。这就是我们将继续使用的定义。
一个复杂的问题
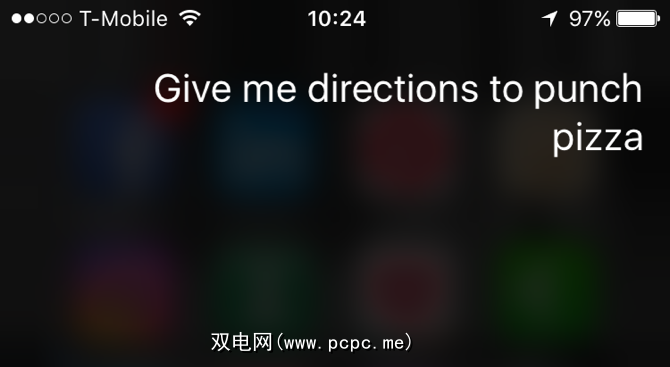
自然语言对于计算机来说很难解决。您可能会说:“ Siri,请给我指示打孔披萨的路线",而我可能会说:“请Siri,请给我打孔披萨的路线。"
在您的声明中,Siri可能会选择关键短语“给我方向",然后运行与搜索字词“ Punch Pizza"相关的命令。但是,在我的Siri中,我需要选择“ route"作为关键字,并且知道“ Punch Pizza"是我要去的地方,而不是“请" "。这只是一个简单的例子。
考虑一种人工智能,它可以读取电子邮件并确定是否可能是欺诈邮件。或者一个监视社交媒体帖子以评估对特定公司的兴趣的人。我曾经在一个项目中工作过,我们必须教一台计算机阅读医学笔记(其中包含各种奇怪的约定)并从中收集信息。
这意味着系统必须能够处理缩写,奇怪的语法,偶尔的拼写错误以及注释中的各种其他差异。这是一个非常复杂的任务,即使是经验丰富的人,甚至是更少的机器,也可能是困难的。
树立榜样
在这个特定项目中,我是团队的一员,计算机识别特定单词以及单词之间的关系。该过程的第一步是向计算机显示每个注释所包含的信息,因此我们对注释进行了注释。
存在大量不同类别的实体和关系。以句子“女士。格林的头痛曾用布洛芬治疗过。" 女士。绿色被标记为PERSON,头痛被标记为SIGN或SYMPTOM,布洛芬被标记为MEDICATION。然后,格林女士因与PRESENTS建立联系而头痛。最终,布洛芬与头痛之间存在TREATS关系。

我们以此方式标记了数千个笔记。我们编写了诊断,治疗,症状,根本原因,合并症,剂量以及您可能想到的与医学有关的所有其他方面的代码。其他注释团队编码了其他信息,例如语法。最终,我们拥有了一个完整的医学注释集,人工智能可以“阅读"。
阅读与理解一样难以定义。计算机可以轻松地看到布洛芬治疗头痛,但是当得知该信息后,它就会转换成对我们来说毫无意义的一和零。它当然可以返回看起来像人的有用信息,但这构成理解吗?再次,这在很大程度上是一个哲学问题。
真实学习
这时,计算机仔细阅读了笔记并应用了许多机器学习算法。程序员开发了不同的例程来标记语音部分,分析依赖性和选区并标记语义角色。从本质上讲,人工智能是在学习“阅读"这些笔记。
研究人员最终可以通过给它提供医学笔记并要求其标记每个实体和关系来对其进行测试。当计算机准确地复制人类注释时,您可以说它学习了如何阅读所述医学笔记。
在那之后,只需收集有关其阅读内容的大量统计信息即可:药物可用于治疗哪些疾病,哪种治疗最有效,特定症状的根本原因等等。在此过程的最后,AI可以根据实际医疗记录中的证据回答医疗问题。它不必依赖教科书,制药公司或直觉。
深度学习
让我们看看另一个例子。谷歌的DeepMind神经网络正在学习阅读新闻报道。就像上面的生物医学AI一样,研究人员希望它能够从较大的文本中提取出相关且有用的信息。
对医学信息进行AI培训非常困难,因此您可以想象要添加多少注释数据需要使AI能够阅读一般新闻文章。雇用足够的注释者和查阅足够的信息将是非常昂贵和费时的。
因此,DeepMind团队转向了另一个来源:新闻网站。特别是CNN和《每日邮报》。
为什么要使用这些网站?因为他们提供了他们文章的要点摘要,而不是简单地从文章本身中提取句子。这意味着AI值得学习。研究人员基本上告诉AI,“这是一篇文章,这是其中最重要的信息。"然后,他们要求AI从一篇文章中提取相同类型的信息,而没有使用突出的符号。
这种复杂程度可以由深度神经网络处理,这是一种特别复杂的机器学习系统。 (DeepMind团队正在该项目上做一些令人惊讶的事情。要获取详细信息,请从《麻省理工学院技术评论》中查看这一出色的概述。)
阅读型AI可以做什么?
我们现在对计算机学习阅读的方式有了大致的了解。您需要花费大量的文字,告诉计算机重要的内容,并应用一些机器学习算法。但是,使用AI从文本中提取信息的AI怎么办?
我们已经知道您可以从医学笔记中提取特定的可行信息并总结一般新闻报道。有一个名为P.A.N.的开源程序通过提取主题和意象来分析诗歌。研究人员经常使用机器学习来分析大量的社交媒体数据,这些数据被公司用来了解用户情绪,了解人们在说什么并找到有用的营销模式。
研究人员已经使用机器学习深入了解电子邮件行为和电子邮件过载的影响。电子邮件提供商可以使用它来过滤收件箱中的垃圾邮件并将某些邮件分类为高优先级。阅读AI对于建立有效的客户服务聊天机器人至关重要。随处可见文本,有研究人员致力于自然语言处理。
随着这种机器学习类型的改进,可能性只会增加。现在,在国际象棋,围棋和视频游戏中,计算机要比人类更好。很快,他们可能会在阅读和学习上变得更好。这是迈向强大AI的第一步吗?我们将不得不拭目以待,但也许是这样。
您看到文本阅读和学习AI有哪些用途?您认为我们将在不久的将来看到什么样的机器学习?在下面的评论中分享您的想法!
图片来源:Vasilyev Alexandr / Shutterstock