
网络抓取工具会自动收集通常只能通过浏览器访问网站才能访问的信息和数据。通过自动执行此操作,Web抓取脚本为数据挖掘,数据分析,统计分析等提供了无限可能。
为什么Web抓取有用
比任何时候都更容易获得信息的时代。
事实上,如此之多的基础是人们正在阅读的这些单词所用的基础结构,是人们获得更多知识,见解和新闻的渠道。
事实上, ,即最聪明的人的大脑提高到100%的效率(应该拍一部电影),仍然仅在美国就无法保存存储在互联网上的数据的1/1000。
所有这些数据和信息都令人生畏。并非所有的事情都是正确的。它与日常生活无关紧要,但是越来越多的设备正在从世界各地的服务器向我们的眼睛和大脑传递这些信息。
由于我们的眼睛和大脑无法真正处理在所有这些信息中,网络抓取已成为一种有用的方法,可以通过编程方式从Internet收集数据。 Web抓取是一个抽象术语,用于定义从网站提取数据以将其保存到本地的行为。
请考虑一种数据类型,您可以通过抓取Web来收集数据。只需编写一个小脚本,就可以找到并保存您所在区域的房地产清单,体育数据,企业电子邮件地址,甚至您最喜欢的歌手的歌词。
浏览器如何获取网络数据?
要了解网络抓取工具,我们首先需要了解网络的工作方式。要访问该网站,您可以在网络浏览器中键入“ PCPC.me",或者单击另一个网页上的链接(告诉我们在哪里,我们很想知道)。无论哪种方式,接下来的几个步骤都是相同的。
首先,您的浏览器将使用您输入或单击的URL(提示:将鼠标悬停在链接上可以看到您底部的URL浏览器之前,请先单击该浏览器,以免收到朋克),然后形成“请求"以发送到服务器。然后,服务器将处理请求并发送回响应。
服务器的响应包含HTML,JavaScript,CSS,JSON和其他数据,以使您的Web浏览器形成一个供您查看的网页
现代浏览器允许我们提供有关此过程的一些详细信息。在Windows上的Google Chrome浏览器中,您可以按 Ctrl + Shift + I 或右键单击并选择检查。然后,窗口将显示一个类似于以下内容的屏幕。
选项卡的选项卡式列表位于窗口顶部。现在值得关注的是网络标签。这将提供有关HTTP流量的详细信息,如下所示。
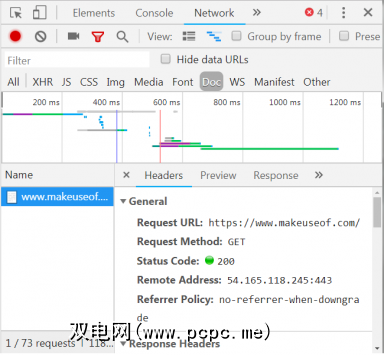
在右下角,我们看到有关HTTP请求的信息。 URL是我们期望的,“方法"是HTTP“ GET"请求。响应中的状态码列为200,表示服务器认为请求有效。
状态码下方是远程地址,该地址是PCPC.me服务器的面向公众的IP地址。 。客户端通过DNS协议获取此地址。
下一部分列出了有关响应的详细信息。响应标头不仅包含状态码,还包含响应所包含的数据或内容的类型。在这种情况下,我们正在寻找具有标准编码的“ text / html"。这告诉我们,响应实际上是用于呈现网站的HTML代码。
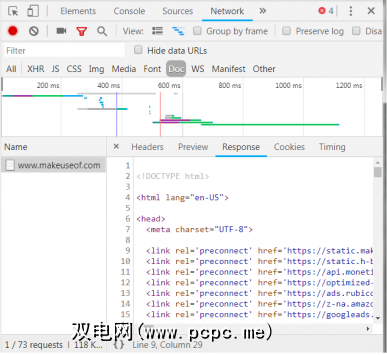
此外,服务器可以将数据对象作为对GET请求的响应而返回,而不仅仅是用于呈现Web页面的HTML。网站的应用程序编程接口(或API)通常使用这种类型的交换。
通过如上所述的“网络"标签,您可以查看是否存在这种类型的交换。在调查CrossFit Open排行榜时,将显示使用数据填充表格的请求。
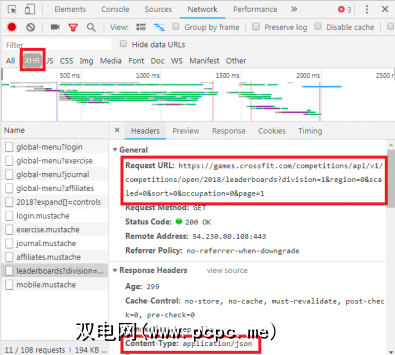
通过单击响应,将显示JSON数据,而不是用于呈现网站的HTML代码。 JSON中的数据是位于分层概述列表中的一系列标签和值。
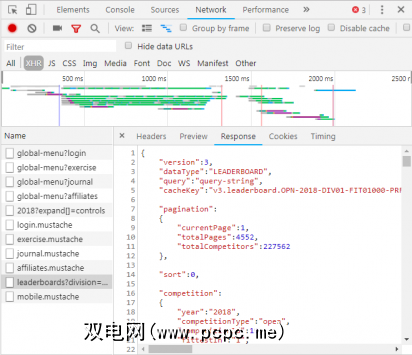
手动解析HTML代码或遍历数千个JSON的键/值对,就像读取矩阵一样。乍一看,看起来像胡言乱语。
Web抓取工具来救援!
现在,在您请求蓝色药丸摆脱困境之前,您应该知道我们不必手动解码HTML代码!无知不是幸福,这条牛排很美味。
网络刮板可以为您执行这些困难的任务。爬网框架可用Python,JavaScript,Node和其他语言提供。开始抓取的最简单方法之一就是使用Python和Beautiful Soup。
只要安装了Python和BeautifulSoup,入门仅需几行代码。这是一个获取网站来源并让BeautifulSoup对其进行评估的小脚本。
from bs4 import BeautifulSoupimport requestsurl = "http://www.athleticvolume.com/programming/"content = requests.get(url)soup = BeautifulSoup(content.text)print(soup)非常简单,我们正在对URL进行GET请求,然后将响应放入对象中。打印对象将显示URL的HTML源代码。就像我们手动访问该网站并单击查看源文件。
具体来说,这是一个每天发布CrossFit风格锻炼的网站,但每个网站仅发布一次天。我们可以构建刮板来每天进行锻炼,然后将其添加到锻炼的汇总列表中。本质上,我们可以创建一个可以轻松搜索的基于文本的锻炼历史数据库。
BeaufiulSoup的魔力在于可以使用内置的findAll()函数搜索所有HTML代码。在这种情况下,网站使用几个“ sqs-block-content"标签。因此,脚本需要遍历所有这些标签并找到我们感兴趣的标签。
此外,该部分中还有许多
标签。该脚本可以将每个标签中的所有文本添加到本地变量中。为此,请向脚本添加一个简单的循环:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n'Voilà! Web抓取工具诞生了。
扩大抓取范围
存在两条前进的路径。
探索Web抓取方法之一是使用已经构建的工具。 Web Scraper(大名!)有200,000个用户,使用简单。此外,Parse Hub允许用户将抓取的数据导出到Excel和Google表格中。
此外,Web Scraper提供了一个Chrome插件,可帮助直观地显示网站的构建方式。最重要的是,按名称判断,OctoParse是一款功能强大的刮板,具有直观的界面。
最后,现在您知道了Web刮板的背景,提出了自己的小型Web刮板以进行爬网和抓取。独自运行是一个有趣的尝试。
标签: Python Web Scraping



.jpg?q=50&fit=contain&w=480&h=300&dpr=1.5)



